Nomad and Consul
A HashiCorp Nomad cluster is blazingly fast and stable. The simplicity of its singular purpose makes for extremely fast container and process scheduling, as well as cluster convergence events. Using the Raft consensus protocol, Nomad is great for running microservices and batch jobs. This blog post will describe deploying a Nomad cluster on AWS with all resources and infrastructure defined as code.
To deploy our Nomad cluster and supporting infrastructure, we can use Cloudformation so everything is defined in code, and so it can be created and maintained via a CI/CD pipeline. Cluster node configuration is executed via AWS’s cloud-init implementation. All bootstrapping instructions are declared in instance metadata, which is then read by the userdata cfn-init process which configures nodes. There are three main resources defined in our template hierarchy:
– Consul and Nomad master nodes, which live as stateful instances, with attached elastic IPs
– Consul and Nomad worker nodes, which live as members of an AutoScaling Group
– Frontend ElasticLoadBalancer, which takes traffic from end users and sends it to the worker nodes.
The full Cloudformation code is on github.
Let’s talk about each of the major components of a Nomad cluster:
Consul is how service registration and discovery happens. Consul can be used as a state backend for a variety of services, but it works great with Nomad. Both are HashiCorp products, and the integration is automatic, as you just specify the Consul endpoint to Nomad. The following shows example services Consul is aware of. We can see it is aware of 3 total Consul masters, and four different Nomad services, each with a different number of scheduled containers and processes:
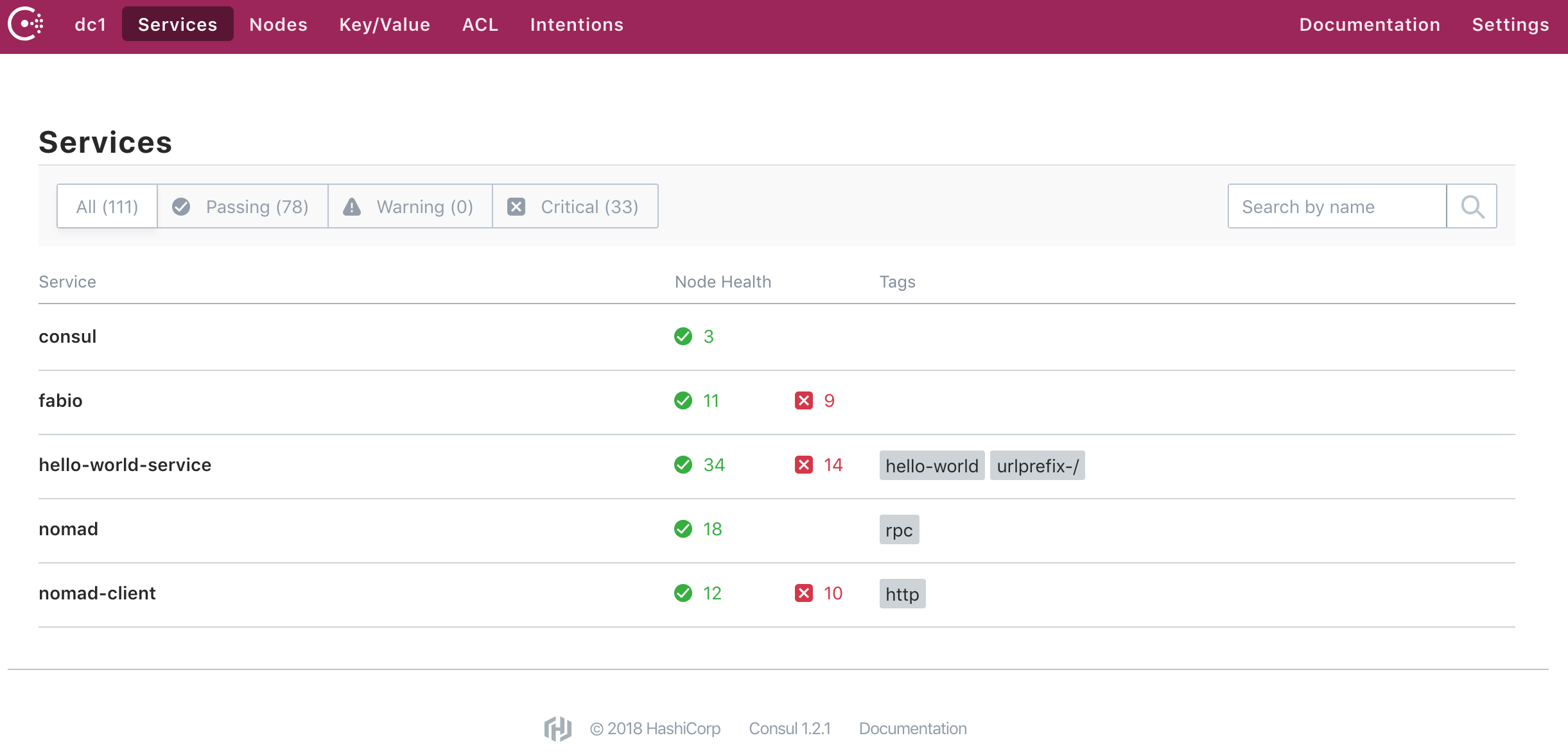
Consul uses the Raft consensus protocol to keep cluster state. This consistent state becomes available to all Consul clients. Once a Nomad service passes the health check, it registers with Consul. We can see the docker port and node IP gets registered for each service, with each healthy instance:
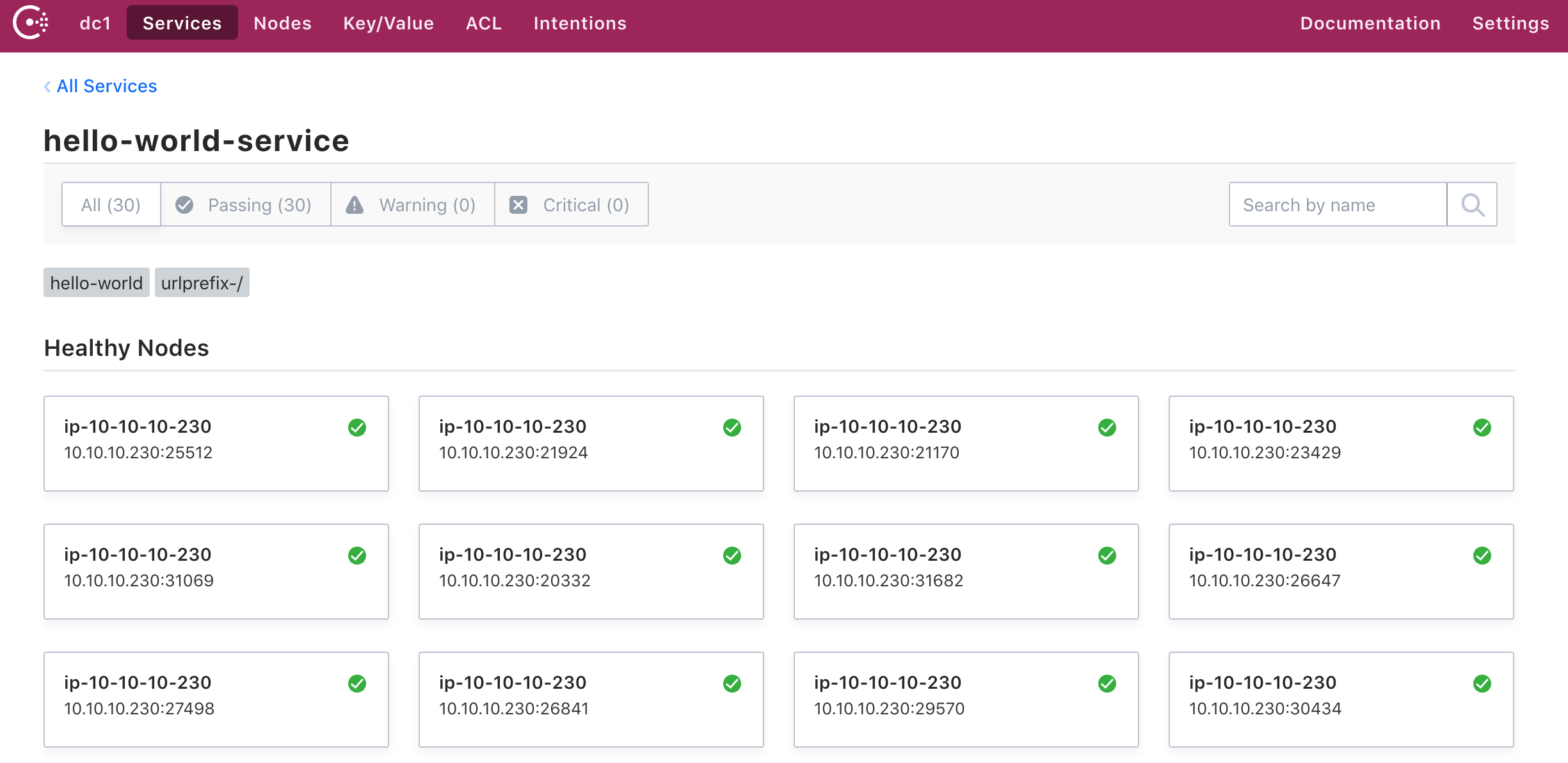
At this point, it becomes very easy for a reverse proxy to poll this information, and send traffic accordingly. We can see the tag “urlprefix-/”. This is the secret sauce that can keep track of each microservice at its own url route. So, for instance, we could create another microservice endpoint at http://URL/v2, by using the tag prefix “urlprefix-/v2”. The example above would just be the root of the URL.
Nomad Masters leverage the Raft consensus protocol, masters keep state for the cluster. They accept jobs, manage clients, and schedule container or process placement.
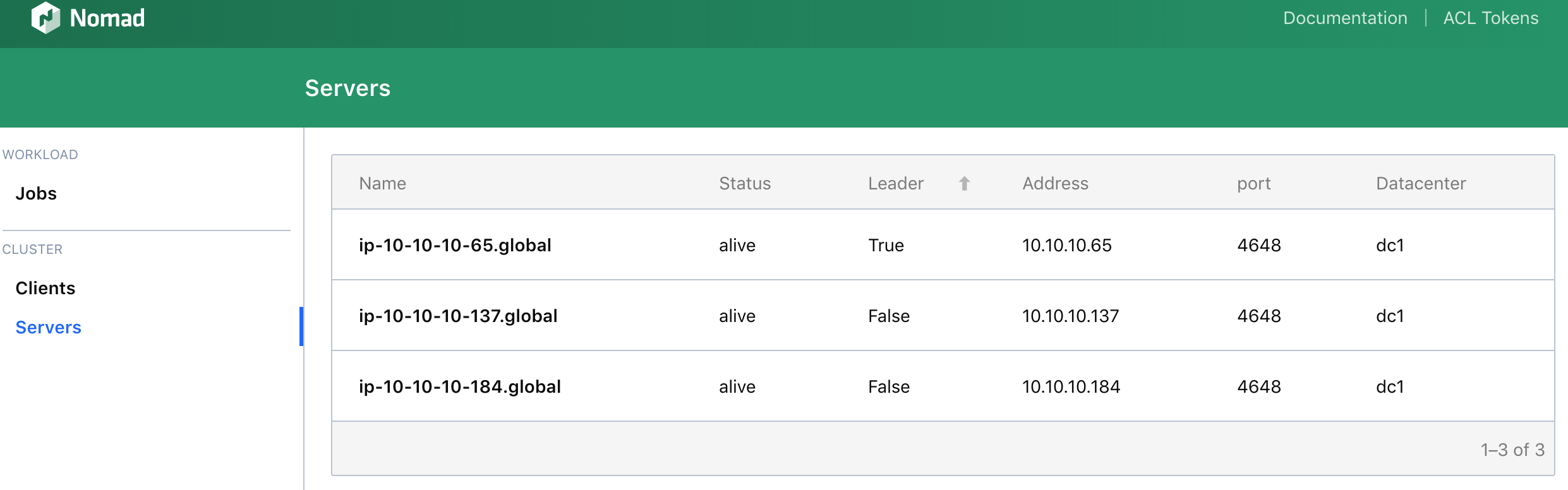
Nomad Workers run both the Nomad and Consul client agents. Consul clients must be told about at least one Consul master, in order to join the cluster. In this way, Nomad workers can simply find the Consul endpoint at localhost.
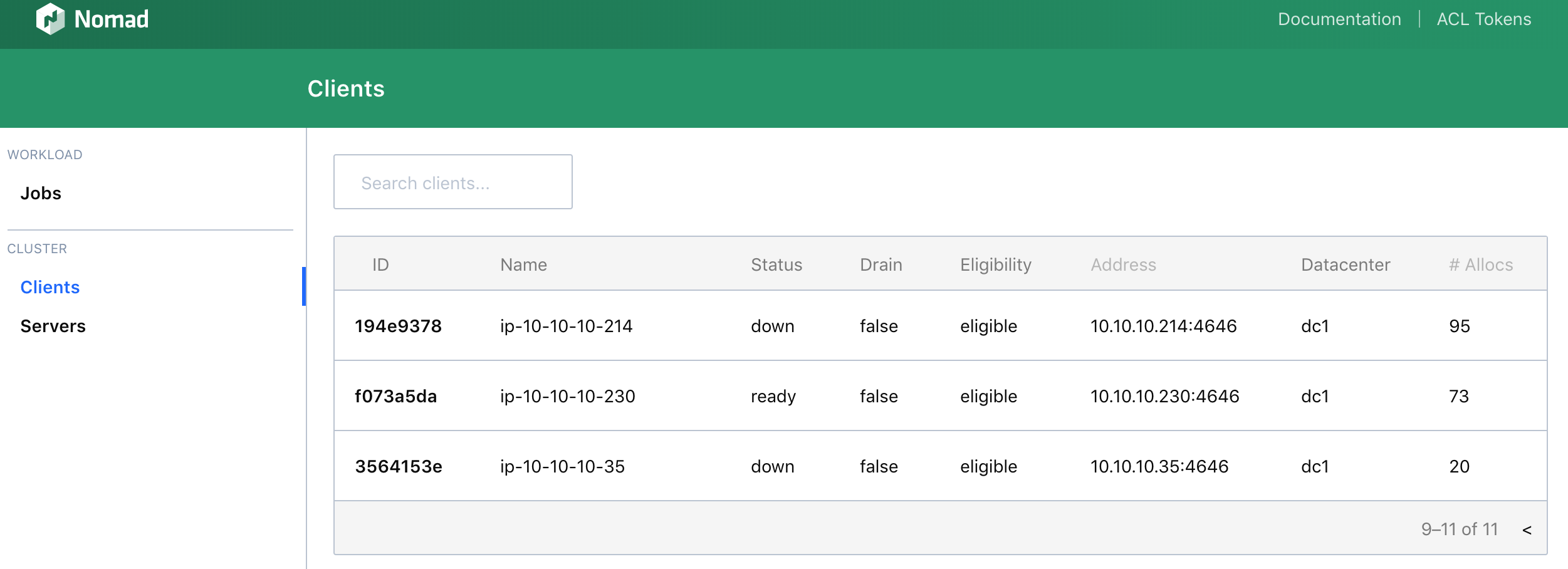
The Routing Mesh handles managing traffic between services. We need a proxy running on our cluster nodes, that will accept traffic from our endusers or loadbalancer, and forward to the correct docker ports running each service. As we saw earlier, this information is registered in Consul, when services are healthy, and so service discovery is available there. Fabio is one such proxy which integrates very well with Nomad and Consul. We need to ensure it runs on every Nomad cluster node, and so we can use the “system” job type to fork exec the Fabio go process on every node. As Nomad worker nodes also run Consul clients, Fabio can just do a localhost lookup to consul.
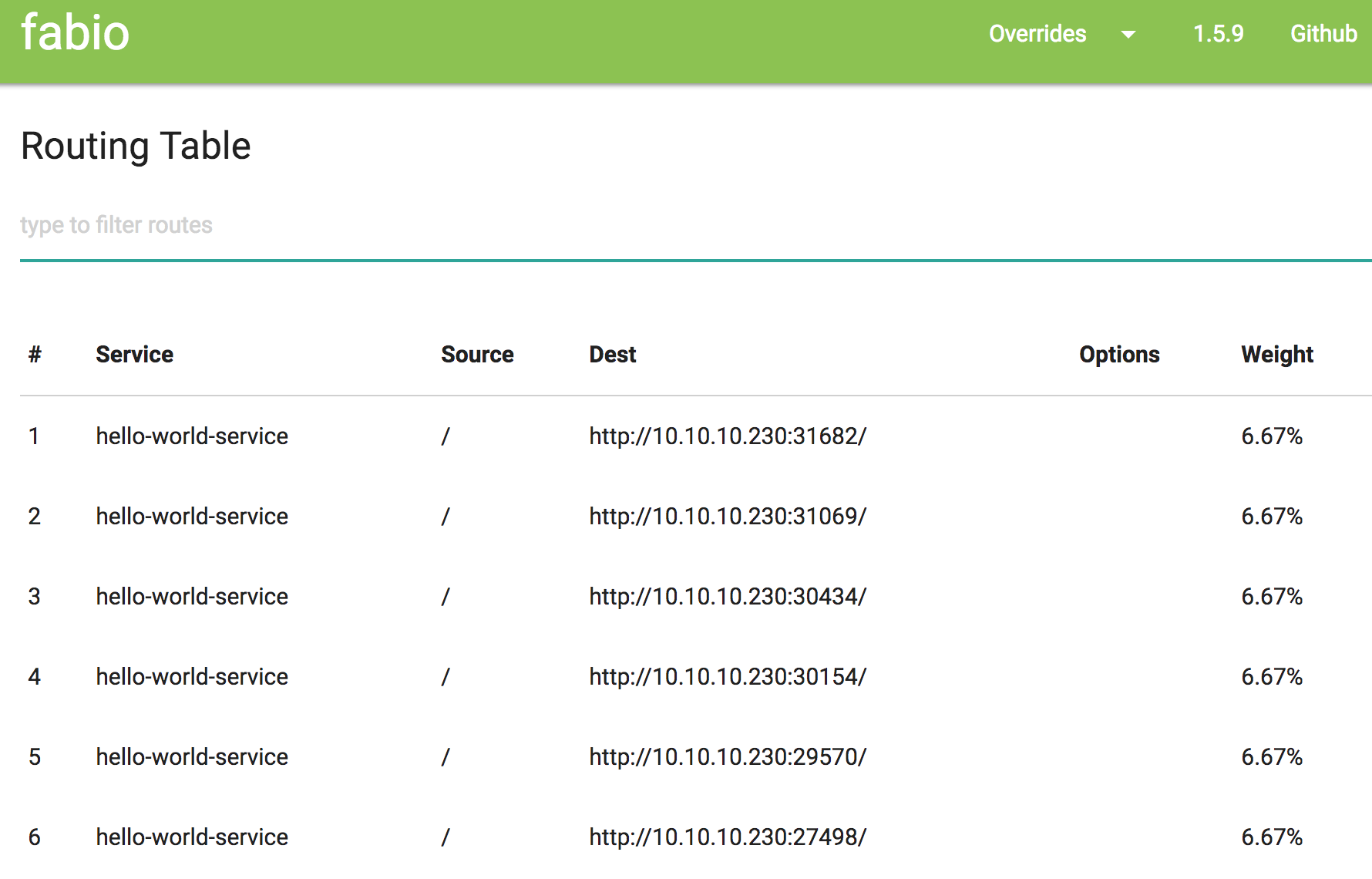
Nomad Service Jobs handle running individual microservices, each with its own URL route. As we mentioned before, Nomad “tags” is the secret behind proper service registration in Consul. We can see below in the example Nomad microservice definition, we want this service to respond to the root of our url: “HTTP://URL/”. The “check” section describes the conditions that need to be met before the service becomes registered with Consul. In this case, a simple http ping to “/” will do:
service {
name = "${TASKGROUP}-service"
tags = ["hello-world", "urlprefix-/"]
port = "http"
check {
name = "hello-world"
type = "http"
interval = "10s"
timeout = "3s"
path = "/"
Nomad Batch Jobs schedule containers or processes to run periodically or on demand, perhaps as part of a Continuous Integration solution. Batch Jobs are where Nomad really shines, as its well thought out and singular focus architecture makes for super fast scheduling. Nomad converges fast when things go wrong with a client node, although running batch jobs do not re-allocate upon node failure, and it is up to the CI orchestration logic to deal with this. By specifying type = "batch" at the top of the job description, Nomad knows this job is not a microservice, and it does not need to register with Consul. Both batch and service jobs rely on a “resources” key which is used to schedule appropriately. The following ensures these minimum resources will be available when scheduling:
resources {
cpu = 100 # Mhz
memory = 16 # MB
network {
mbits = 1
}
Nomad System Jobs ensure a single instance of a container or process is running on every Nomad node. This is the mechanism by which we deployed Fabio earlier. If every node needs to run some additional process or container, type = "system" is the answer. For full examples of each of the jobs, as described in HCL (HashiCorp Configuration Language), check out the github repo.
Nomad is a great container clustering solution, as it is very small and fast. There is no bloat which makes it perfect as a building block in a CI/CD solution. For more information on just how performant HashiCorp Nomad is, check out the Million Container Challenge
cheers,
@hackoflamb

|
Stelligent Amazon Pollycast
 |